BakLLaVA multimodal inference with llama.cpp (Mistral + CLIP)
BakLLaVA is a Mistral-based LLaVA model that can describe images using a CLIP vision encoder. This guide walks through the exact GGUF files you need and a working llama.cpp + PyLLMCore setup. If you are searching for the “BakLLaVA model” quickstart, start here.
Haotian Liu, Chunyuan Li et al. introduced a few weeks ago LLaVA, Large Language and Vision Assistant. This is a multimodal model connecting a vision encoder and a LLM. They combined LLaMA 2 with CLIP (Contrastive Language–Image Pre-training) to make a LLM capable of managing images.
Skunkworks AI released a model based on Mistral AI (instead of LLaMA 2) under the name BakLLaVA (like the mediterranean pastry). As I find Mistral to be very powerful, this is a perfect match.
Let's achieve a simple goal: Ask the LLM to describe an image.
Prerequisites
We'll run the code locally with the help of llama.cpp, llama-cpp-python binding and the PyLLMCore high level library.
python3 -m venv
source venv/bin/activate
pip install py-llm-coreNext, we'll need the model weights. I already converted BakLLaVA to GGUF and perform quantization (Q4_K_M) so the only thing to do is to download these 2 files from the Hugging face repository :
- BakLLaVA-1-Q4_K_M.gguf
- BakLLaVA-1-clip-model.gguf
Note: clip model is the multimodal projector (the terminology is somehow complex for non-experts).
Troubleshoot llama-cpp-python bindings
Sometimes the installation process of the dependency llama-cpp-python fails to identify the architecture on Apple Silicon machines. You may need to run the following:
pip install --upgrade --verbose --force-reinstall --no-cache-dir llama-cpp-pythonSample code to describe an image
Create a file named main.py and write:
from llm_core.llm import LLaVACPPModel
model = "BakLLaVA-1-Q4_K_M.gguf"
llm = LLaVACPPModel(
name=model,
llama_cpp_kwargs={
"logits_all": True,
"n_ctx": 8000,
"verbose": False,
"n_gpu_layers": 100, #: Set to 0 if you don't have a GPU
"n_threads": 1, #: Set to the number of available CPU cores
"clip_model_path": "BakLLaVA-1-clip-model.gguf"
}
)
llm.load_model()
history = [
{
'role': 'user',
'content': [
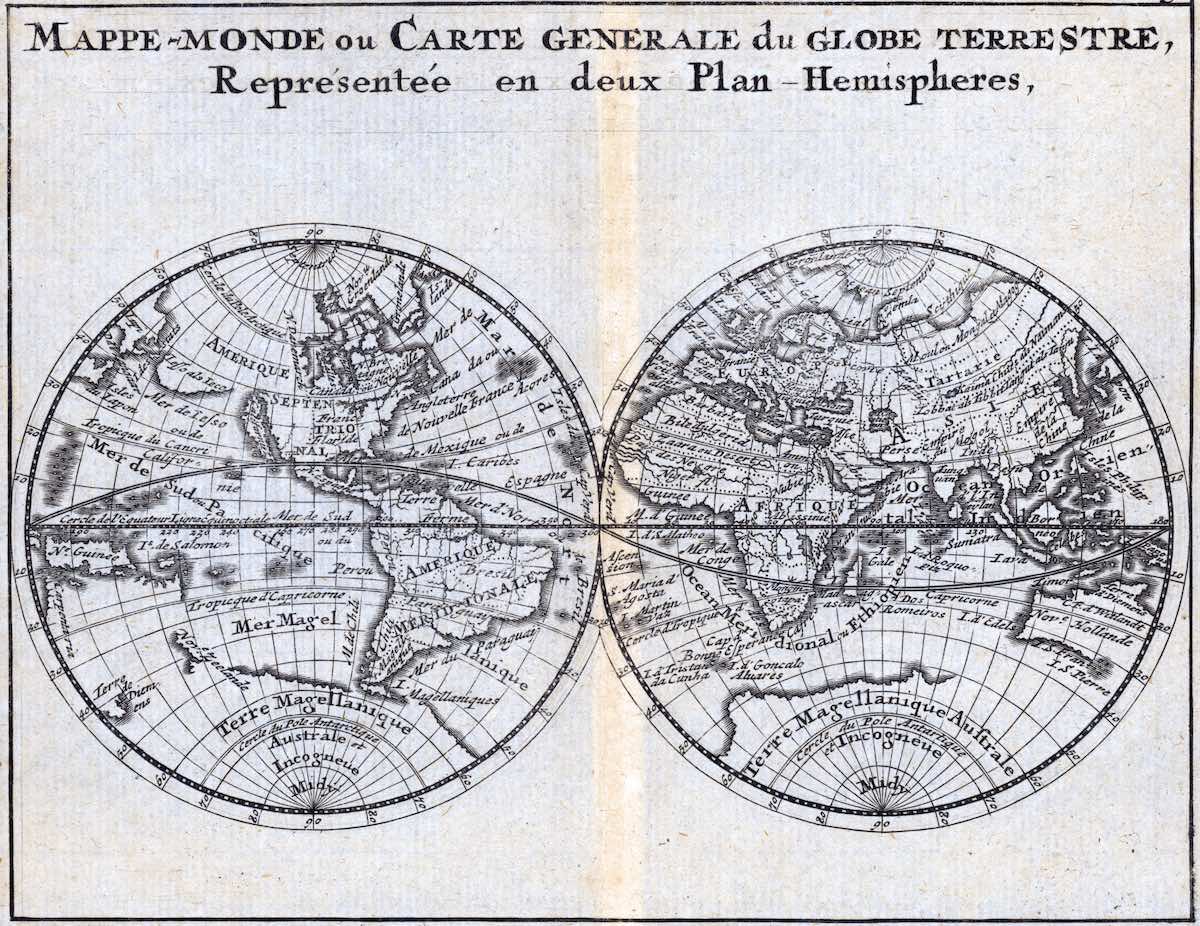
{'type': 'image_url', 'image_url': 'https://advanced-stack.com/assets/img/mappemonde.jpg'}
]
}
]
response = llm.ask('Describe the image as accurately as possible', history=history)
print(response.choices[0].message.content)The image features two antique maps of the world, drawn by hand and
placed side by side. These old-fashioned globe maps showcase the
cartography of a past era. The first map is positioned on the left
side of the image, while the second map is located on the right side.
The two maps display different continents and oceans, with various
countries and their boundaries visible. The cartographic details on
the maps provide a glimpse into the geographical knowledge of the
time when they were created.
Overall, the image offers an interesting comparison between the two
historical world maps.And voilà !
Next steps
Read more...
You might be interested by related articles: