Teaching Large Language Models how to generate workflows (2/n)
See first part here: How to build Trigger-Action workflows with LLMs - Part 1
To generate workflows that can work with any kind of workflow engines, a high-level abstraction can help. It's even better if the explanations of the abstraction is part of the training dataset. That's why I selected Colored Petri Nets.
A quick verification of the training dataset of smaller language models will help a lot when selecting a model. llama-3.1-8b-q4 answered with great details and I will use it in the next steps.
Colored Petri Nets with LLMs - Structures all the way down
To improve the results and make a step forward a more concrete workflow (but not yet runnable), we'll pave a railway to force the model generate valid configurations. The description fields we had in previous data classes in part 1 were simple strings. We'll use structured outputs as reins on the LLM to stay within valid generations.
The initial modeling of workflow was a naive approach and we'll implement Colored Petri Nets with some adaptations to yield robust results.
Colored Petri Nets (CPNs) are a mathematically grounded extension of classical Petri nets designed to model complex workflows involving data, conditions, and concurrent activities.
In a CPN:
- Tokens carry data values (colors)
- Places are token containers. Coupled with tokens they represent the state of the whole system
- Transitions move or create tokens from input to output places according to guards
- Guards are conditions that must be true for a transition to fire
- Arcs are connectors that links a place to a transition + new place, showing token flow direction: These are pipes carrying tokens
This enables workflows where decisions, routing, and processing depend not only on where the tokens are, but what they contain.
For example, using the Tesla charging query and environment we'd model the environment as follows.
Places and Tokens
I make a distinction between place types to force data flows: sources and sinks.
In our environment we have:
- Power company
- A power charger (contains the plug sensor)
- The Tesla monitoring system that gives the remaining range
Let's start with tokens, actually token types (colors):
remaining_range = TokenType(name="remaining_range", type="INT")
charger_enabled = TokenType(name="charger_enabled", type="BOOL")
car_plugged = TokenType(name="car_plugged", type="BOOL")
electricity_price = TokenType(name="electricity_price", type="FLOAT")Now with places
Place(
name="Power company",
description="Provides current electricity price",
type="source",
token_type=electricity_price,
)Place(
name="Power charger (plug sensor)",
description="Provides the status of the plug",
type="source",
token_type=car_plugged,
)Place(
name="Power charger",
description="Charge electric vehicles",
type="sink",
token_type=charger_enabled,
)Place(
name="EV monitoring system (range)",
description="Provides the remaining range in miles",
type="source",
token_type=remaining_range,
)Transitions, Arcs and Guards
Let's analyze the query When the electricity price is below $0.4/kWh and my Tesla is plugged, turn on charging. However, whatever the price I always need to have a minimum range of 100 miles.
I tested different open source models like llama-3.1-8b, mistral-7b-0.3, and qwen3-4b but also gpt-4.1-nano, gpt-4.1-mini and gpt-4.1. Only gpt-4.1 managed to understand and map the second part of the query (minimum range of 100 miles).
Smaller models completely ignored the second part and at some point got the logic all wrong (charging the EV only when the remaining range was above 100 miles).
It was both funny and enraging to see how they failed. Here's an extract of the reasoning process of Qwen3:
... Wait, the user's query says that regardless of the price, the range must be at least 100. So the charging can only start if the range is >= 100. Therefore, the transition that enables the charger must have a guard that checks both the price, the plug status, and the range...
gpt-4.1 was actually quite good at modeling the correct transitions when prompted with very detailed instructions (from llm-tap).
transition EnableChargingByPrice
goal: Enable charging when price is low and car is plugged, and range is sufficient.
change: Set charger_enabled to true if electricity_price < 0.4, car_plugged is true, and remaining_range >= 100.
--
in: Power_company[price],
in: Power_charger_plug_sensor[plugged],
in: EV_monitoring_system_range[range]
guard: price < 0.4 and plugged = true and range >= 100
out: Power_charger[Set charger_enabled to true]
end transition
// Transition: Enable charging by low range
transition EnableChargingByLowRange
goal: Enable charging if remaining range is below minimum, regardless of price.
change: Set charger_enabled to true if remaining_range < 100 and car_plugged is true.
--
in: EV_monitoring_system_range[range],
in: Power_charger_plug_sensor[plugged]
guard: range < 100 and plugged = true
out: Power_charger[Set charger_enabled to true]
end transitionThe actual data structures (from llm-tap) to model transitions are the following (simplifed for brevity):
@dataclass
class InputArc:
place: Place
token_name: str
transition: str
@dataclass
class OutputArc:
place: Place
produce_token: TokenValue
transition: str
@dataclass
class Condition:
operator: str
value: TokenValue
@dataclass
class Guard:
name: str
conditions: list[Condition]
conditions_operator: str
@dataclass
class Transition:
name: str
state_change: str
inputs: list[InputArc]
outputs: list[OutputArc]
guard: list[Guard]Going back to smaller models, we'll keep our queries small ; in a later stage we might have to split queries and then merge different generated workflows. For the time being, let's get llama 3 8b generate our Petri net.
Workflow generated with llama-3.1-8b
The following code generates our workflow:
from llm_tap import llm
from llm_tap.models import (
Workflow,
Place,
TokenType,
instructions,
register_place,
register_token_type,
get_places,
)
remaining_range = TokenType(name="remaining_range", type="INT")
charger_enabled = TokenType(name="charger_enabled", type="BOOL")
car_plugged = TokenType(name="car_plugged", type="BOOL")
electricity_price = TokenType(name="electricity_price", type="FLOAT")
register_token_type(remaining_range)
register_token_type(charger_enabled)
register_token_type(car_plugged)
register_token_type(electricity_price)
register_place(
Place(
name="Power company",
description="Provides current electricity price",
type="source",
token_type=electricity_price,
)
)
register_place(
Place(
name="Power charger (plug sensor)",
description="Provides the status of the plug",
type="source",
token_type=car_plugged,
)
)
register_place(
Place(
name="Power charger",
description="Charge electric vehicles",
type="sink",
token_type=charger_enabled,
)
)
register_place(
Place(
name="EV monitoring system (range)",
description="Provides the remaining range in miles",
type="source",
token_type=remaining_range,
)
)
system_prompt = instructions
prompt = """When the electricity price is below $0.4/kWh and my Tesla
is plugged, turn on charging."""
model = "~/.cache/py-llm-core/models/llama-3.1-8b"
with llm.LLamaCPP(model=model, n_ctx=8_000) as parser:
workflow = parser.parse(
data_class=Workflow,
prompt=prompt,
system_prompt=system_prompt,
)
print(workflow)The previous code prints:
Workflow(
name="Workflow",
query="When the electricity price is below $0.4/kWh and my Tesla is plugged, turn on charging.",
transitions=[
Transition(
name="Turn on charging",
state_change="Change",
inputs=[
InputArc(
place=Place(
name="Power company",
description="Provides current electricity price",
type="source",
token_type=TokenType(
name="electricity_price", type="FLOAT"
),
),
token_name="electricity_price",
transition="Turn on charging",
),
InputArc(
place=Place(
name="Power charger (plug sensor)",
description="Provides the status of the plug",
type="source",
token_type=TokenType(name="car_plugged", type="BOOL"),
),
token_name="car_plugged",
transition="Turn on charging",
),
],
outputs=[
OutputArc(
place=Place(
name="Power charger",
description="Charge electric vehicles",
type="sink",
token_type=TokenType(
name="charger_enabled", type="BOOL"
),
),
produce_token=TokenValue(
type=TokenType(name="charger_enabled", type="BOOL"),
value="True",
),
transition="Turn on charging",
)
],
guard=[
Guard(
name="Turn on charging",
conditions=[
Condition(
operator="LESS THAN",
value=TokenValue(
type=TokenType(
name="electricity_price", type="FLOAT"
),
value="0.4",
),
),
Condition(
operator="EQUAL",
value=TokenValue(
type=TokenType(
name="car_plugged", type="BOOL"
),
value="True",
),
),
],
conditions_operator="AND",
)
],
)
],
)When converting the user's query into a full fledged workflow (using llm-tap v0.1.0) and converting the result to a mermaid graph:
from llm_tap.to_mermaid import workflow_to_mermaid
print(workflow_to_mermaid)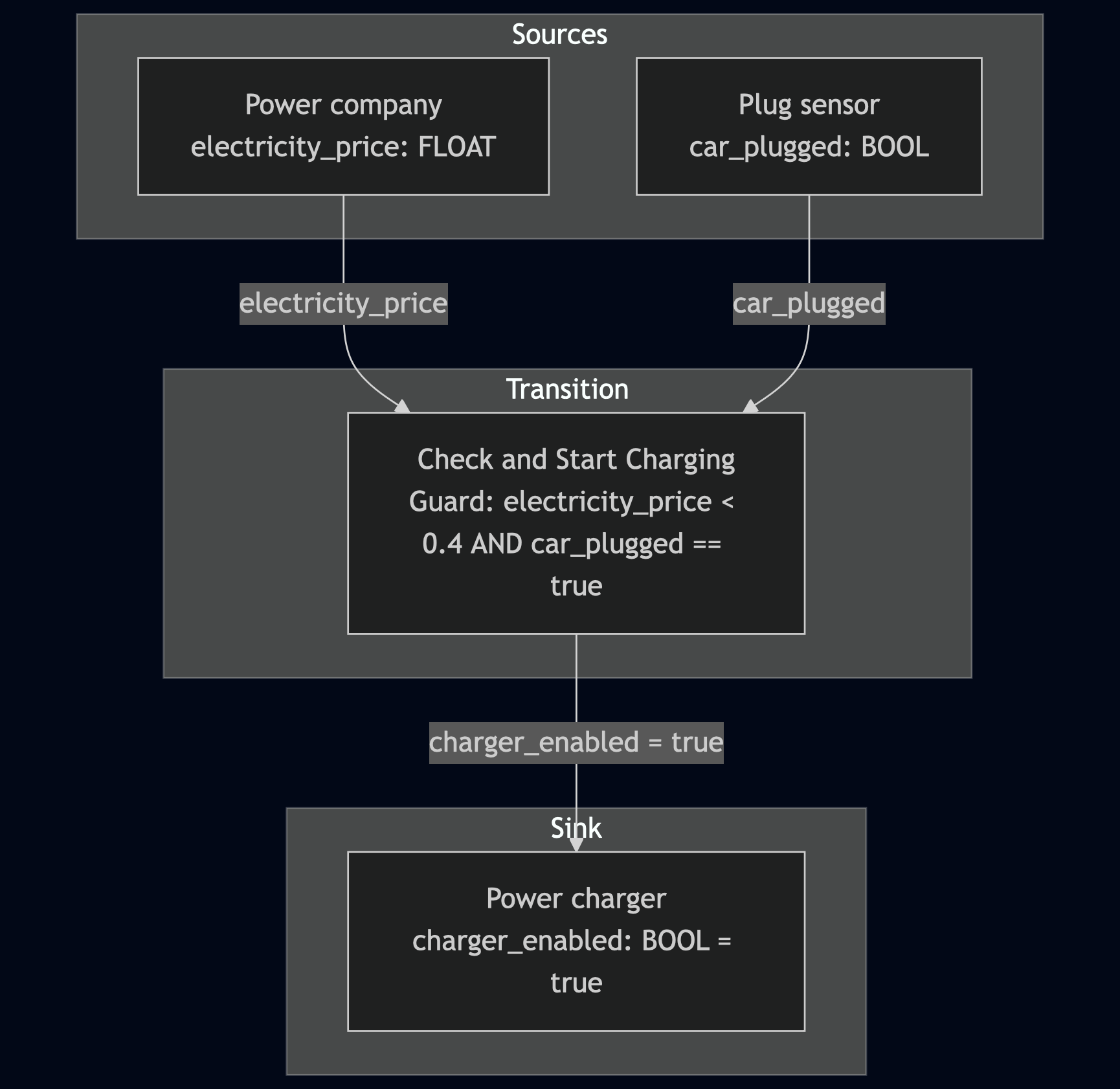
Lessons learnt along the way
What went wrong when working with small models
Going back and forth on the logic itself and the structured graph with small models was a pain. As stated previously, smaller models (< 4B) are a poor fit for logic reasoning and produce erroneous outputs. Even with strict structures to guide them, the logic itself was flawed (even with reasoning models such as the Qwen 3 series).
I tried another route: Use a larger model (8B) to produce unrestricted text describing the Petri Net and then in a second stage use a small one (0.5B, 1B, 3B) to parse the results into the structure. The attempt failed as the smaller models did not capture the complete graph.
When tweaking the user query is key
When tweaking the user query - the one thing I didn't want to do I actually got much better results. For example, when I asked for the system to charge the car unconditionally to get an autonomy of at least 100 miles, small models were able to capture and generate a correct workflow.
Larger models are better suited for vague queries: they are simply smarter.
First conclusions
I've been working with LLMs extensively since 2022 and even if small models are getting better (Llama 3 and Qwen 3 are really good), I would not recommend to use them in applications where logic reasoning is required.
For simple logic, 8B models may be a good fit, otherwise, they are only good at conversing, translating already well formulated queries into other statements (parsing, ...).
In the next part, we'll cover the integration of our workflow generator with the IoX energy automation system, i.e. generate a runnable workflow on ISY (See NuCoreAI)
See part 3 here