Ensuring resilience from day one : Building gzip.cloud
In 2016, I accidentally deleted 30 TB of client data. I did not sleep until we restored everything. That week burned the lesson into me: backups are not a checkbox, they are a promise.
More recently, I felt a weird nostalgia when I recovered my early backups from the 2000s. I had saved a lot: first programs, student projects, old drafts.
I did a decent job for the time. But the medium was wrong. DVDs were a terrible idea. I restored only half of my music, and I had to use Archive.org to recover the other essential mixes from Radio One.
I am currently building gzip.cloud, a remote backup service optimized for single-tenant simplicity. Off-site by default, predictable by design.
The name was a reflex. I bought the domain without thinking because it echoes the Unix philosophy I trust most: do one thing and do it right.
This is the first public draft of the service I want to run. The priorities are:
- Low man-hours
- High resilience
- High reliability
- Simple observability
Everything else is noise. The north star is a higher signal-to-noise ratio than anything I have seen in backup land.
The core idea
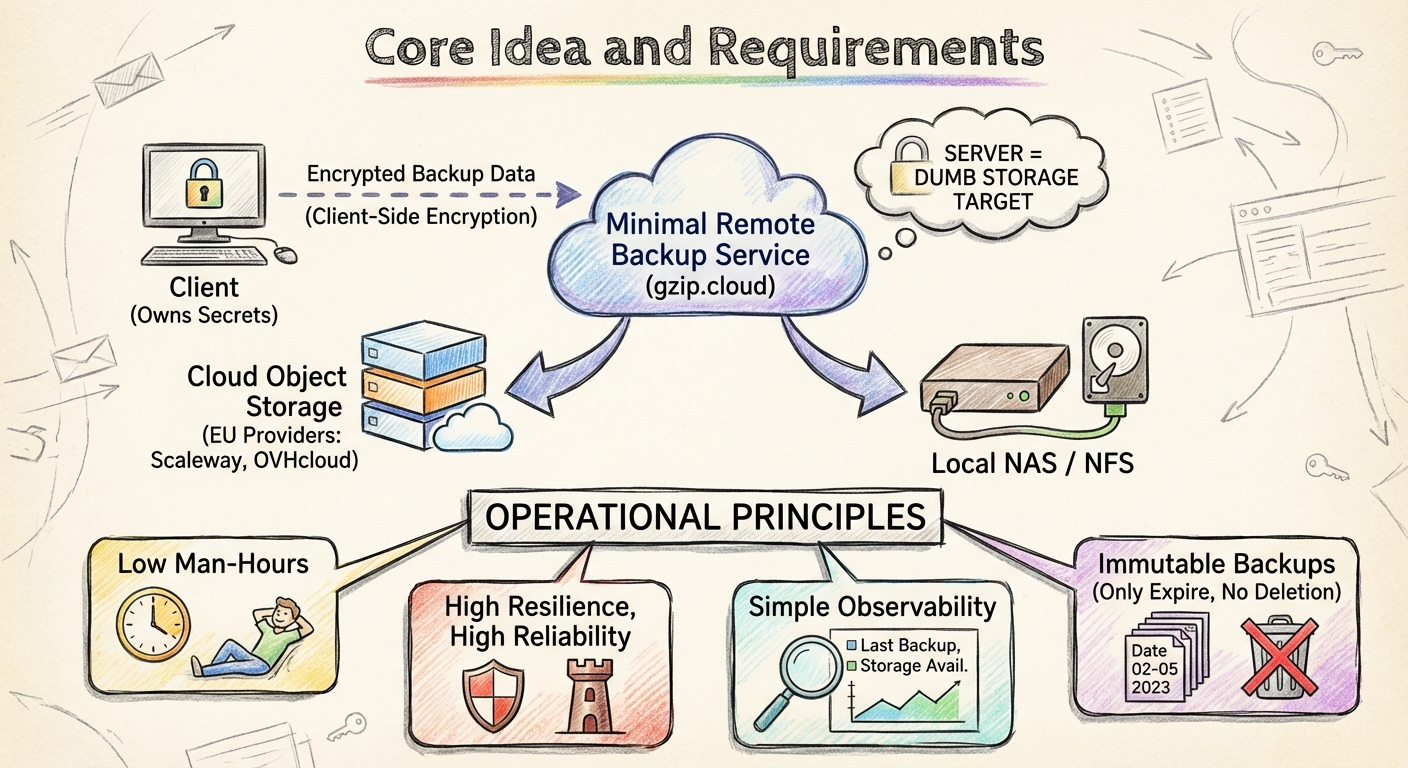
A backup service has two jobs: receive backups and make restores reliable.
Everything else is optional. If a feature cannot justify its operational tax, it does not belong.
Storage: off-site and EU-first
I do not exclude cloud object storage.
It is a pragmatic choice for off-site durability. I plan to use both Scaleway and OVHcloud because I target the EU market and I want provider diversity without enterprise overhead.
For on-prem (remote) setups (i.e. gzip.local), I keep it boring: Any hardware box able to host 2 drives. If I have spare RAM, I'll use ZFS.
It is predictable, well understood, and easy to replace.
Both gzip.cloud and gzip.local will use the same frontend API.
The API and frontend: minimal by design
This is the part that interests me most right now. I am leaning toward restic over SFTP because it keeps the surface area small and the UI thin:
- One tenant equals one set of SSH public keys
- User management is just key management
- No tokens, no OAuth, no IAM maze
Encryption: client-side or nothing
Encryption happens on the client. If I am shipping data off-site, I do not want to trust server-side encryption in the first place. The server is a dumb storage target; the client owns the secrets.
The security model (simple by design)
Backups cannot be deleted or overwritten by the user. They only expire. That single rule removes an entire class of mistakes and attacks, and it keeps the security model honest and easy to reason about. Restores are deliberately simple too:
- If a client has the SSH access key and the decryption key, it can restore
- This is a backup service, not a vault
- The service never sees data in clear and never needs your decryption key
I will keep those keys separate. It is the same principle as the two-keys system to launch an ICBM: access alone is not enough, encryption alone is not enough, you need both.
It is also a good idea to print the SSH key (encrypted with a passphrase) on paper, with a QR code to make recovery and copying less error-prone.
What I actually monitor
I do not want dashboards. I want answers. I care about a short list of high-signal checks:
- Last successful backup
- Last successful restore test
- Storage availability
- Capacity headroom
- Unexpected SSH key activity
If those are green, I am safe.
What the day-to-day looks like
Most days, nothing happens. That is the goal. I scan a short checklist:
- Last backup
- Last restore drill
- Storage health
- Key activity
If something is red, I fix the root cause, not the symptom.
The rest is hygiene:
- Rotate keys
- Prune expired backups on schedule
- Run restore drills so I never lose confidence in the system
When the system is simple, this fits in a very small operational window each week. If I start spending time on dashboards, it usually means the design is not minimal enough.
Where an AI agent fits (only on stats/metrics)
I want an agent on the metadata side only. No access to data. No secrets. No restore keys. Its job is to reduce noise:
- Summarize backup outcomes
- Highlight anomalies
- Suggest next actions
Think: missed backup windows, restore drills that are slowing down, or key activity that looks unusual.
It should deliver a short daily summary and nothing more. It should never touch the data plane. Maybe the agent will also help with support. I find that documentation plus AI agents are a real plus.
What the service feels like for a customer
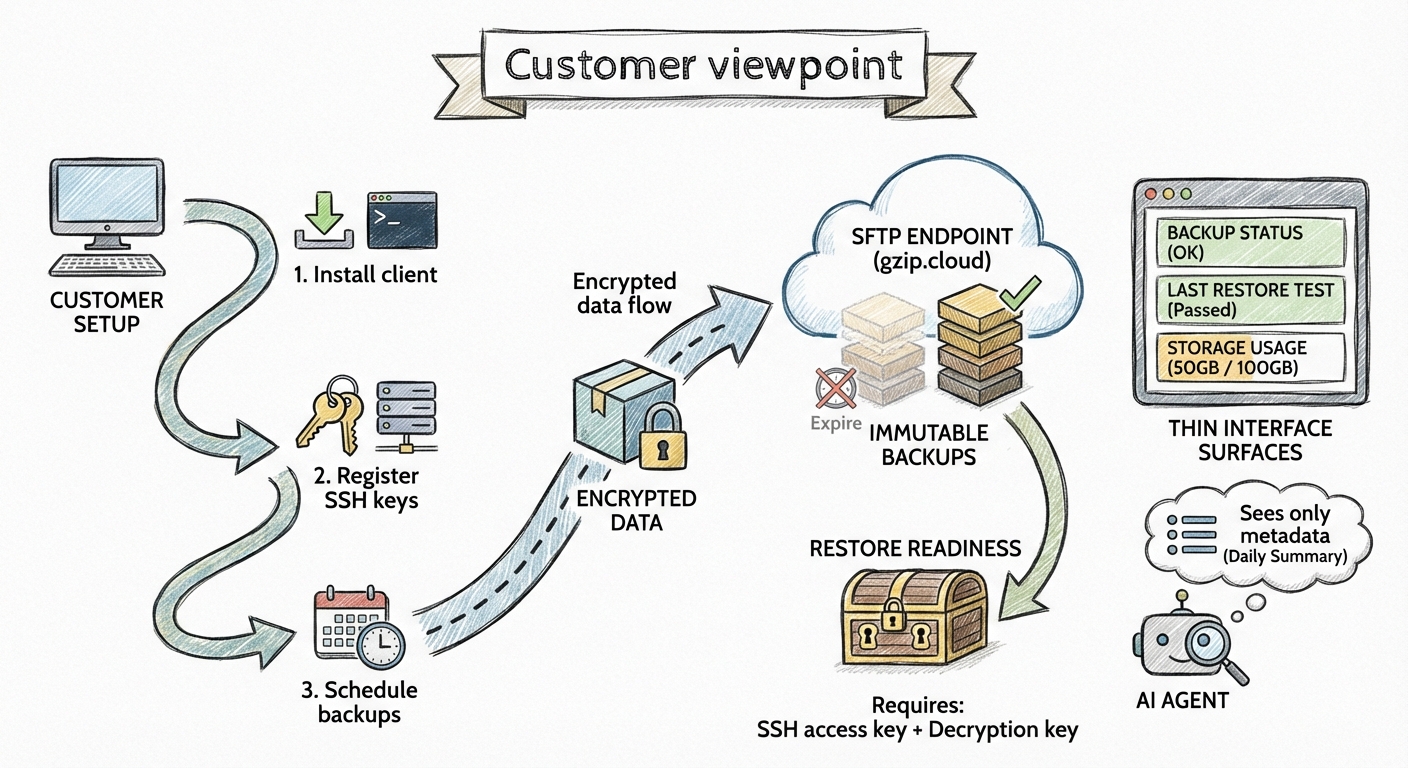
From a customer’s point of view, the service should feel almost boring. The flow is simple:
- Install a client
- Add a target
- Register SSH keys
- Schedule backups
The interface is thin by design: backup status, last restore test, and storage usage. Everything else is optional.
For internal use, I want a short runbook, a small dashboard, and a restore drill I can trust. The system is there when I need it and invisible when I do not.
For external customers, the promise is clear: point restic to our SFTP endpoint, ship encrypted data, and keep your own keys.
If we cannot restore, nothing else matters.